Lets now write the code necesary for our compute shader. We will begin with a very simple shader that has an image as input, and writes a color to it, based on the thread ID, forming a gradient. This one is already on the code, in the shaders folder. From now on, all the shaders we add will go into that folder as the CMake script will build them.
gradient.comp
//GLSL version to use
#version 460
//size of a workgroup for compute
layout (local_size_x = 16, local_size_y = 16) in;
//descriptor bindings for the pipeline
layout(rgba16f,set = 0, binding = 0) uniform image2D image;
void main()
{
ivec2 texelCoord = ivec2(gl_GlobalInvocationID.xy);
ivec2 size = imageSize(image);
if(texelCoord.x < size.x && texelCoord.y < size.y)
{
vec4 color = vec4(0.0, 0.0, 0.0, 1.0);
if(gl_LocalInvocationID.x != 0 && gl_LocalInvocationID.y != 0)
{
color.x = float(texelCoord.x)/(size.x);
color.y = float(texelCoord.y)/(size.y);
}
imageStore(image, texelCoord, color);
}
}
We begin by specifying a default glsl version, 460 which maps to GLSL 4.6 will do just fine.
Next we have the layout statement that defines the workgroup size. As explained in the article before, when executing compute shaders, they will get executed in groups of N lanes/threads. We are specifying sizes x=16, y=16, z=1 (default). Which means that in the shader, each group will be of 16x16 lanes working together.
The next layout statement is for the shader input through descriptor sets. We are setting a single image2D as set 0 and binding 0 within that set. With vulkan, each descriptor set can have a number of bindings, which are the things bound by that set when you bind that set. So this is 1 set, at index 0, which will contain a single image at binding #0.
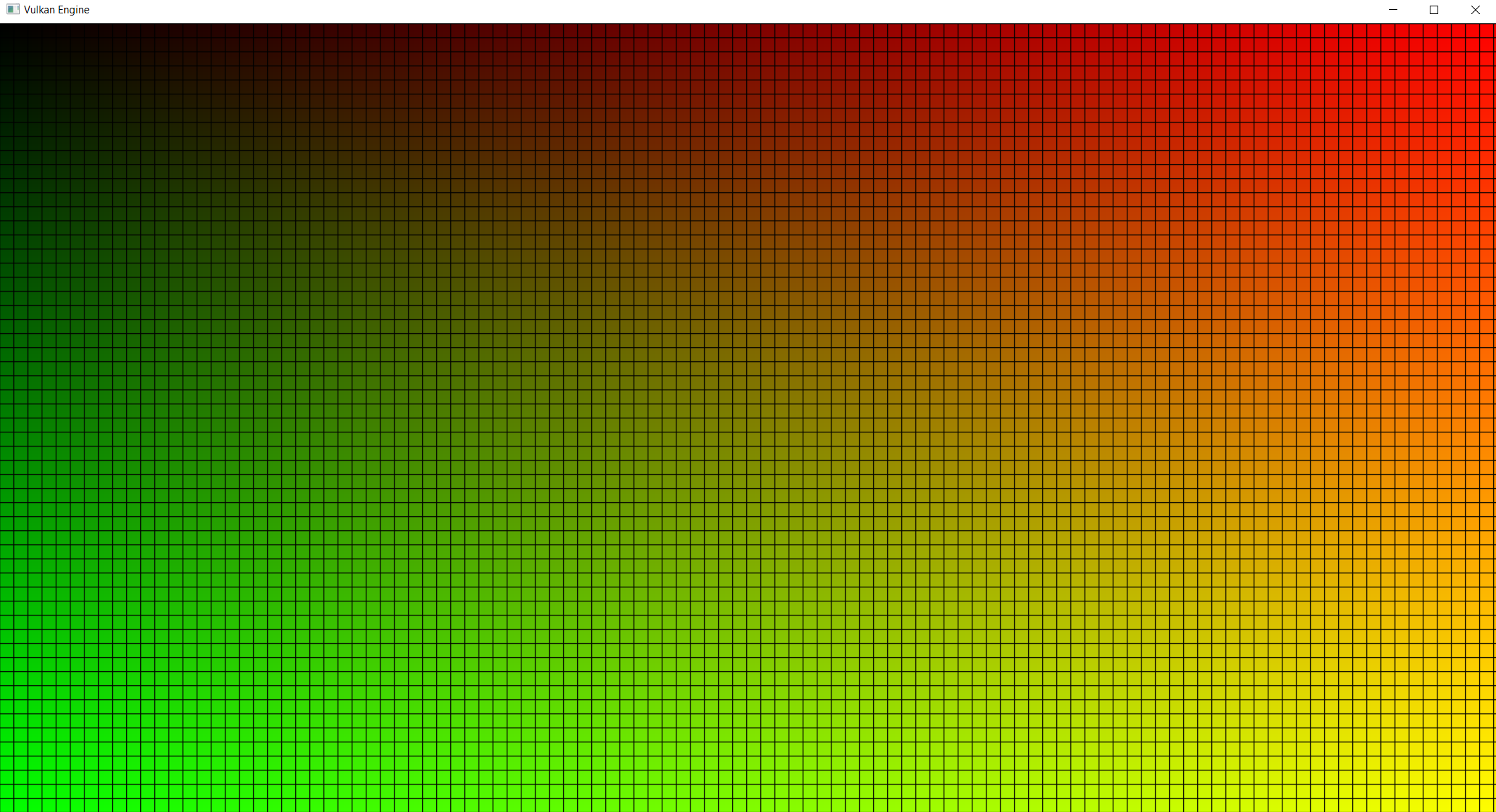
The shader code is a very simple dummy shader that will create a gradient from the coordinates of the global invocation ID. If local invocation ID is 0 on either X or Y, we will just default to black. This is going to create a grid that will directly display our shader workgroup invocations.
Any time you touch the shaders, make sure you compile the shaders target from the build, and if you add new files, you must re-configure the cmake. This process has to succeed with no errors, or the project will be missing the spirv files necesary to run this shaders on the gpu.
Setting up the descriptor layout
To build the compute pipeline, we need to create its layout. In this case, the layout will only contain a single descriptor set that then has a image as its binding 0.
To build a descriptor layout, we need to store an array of bindings. Lets create a structure to abstract this so that handling those is simpler. Our descriptor abstractions will go into vk_descriptors.h/cpp
struct DescriptorLayoutBuilder {
std::vector<VkDescriptorSetLayoutBinding> bindings;
void add_binding(uint32_t binding, VkDescriptorType type);
void clear();
VkDescriptorSetLayout build(VkDevice device, VkShaderStageFlags shaderStages, void* pNext = nullptr, VkDescriptorSetLayoutCreateFlags flags = 0);
};
We will be storing VkDescriptorSetLayoutBinding, a configuration/info struct, into an array, and then have a build() function which creates the VkDescriptorSetLayout, which is a vulkan object, not a info/config structure.
Lets write the functions for that builder
void DescriptorLayoutBuilder::add_binding(uint32_t binding, VkDescriptorType type)
{
VkDescriptorSetLayoutBinding newbind {};
newbind.binding = binding;
newbind.descriptorCount = 1;
newbind.descriptorType = type;
bindings.push_back(newbind);
}
void DescriptorLayoutBuilder::clear()
{
bindings.clear();
}
First, we have the add_binding function. This will just write a VkDescriptorSetLayoutBinding and push it into the array. When creating a layout binding, for now we only need to know the binding number and the descriptor type. With the example of the compute shader above, thats binding = 0, and type is VK_DESCRIPTOR_TYPE_STORAGE_IMAGE, which is a writeable image.
Next is creating the layout itself
VkDescriptorSetLayout DescriptorLayoutBuilder::build(VkDevice device, VkShaderStageFlags shaderStages, void* pNext, VkDescriptorSetLayoutCreateFlags flags)
{
for (auto& b : bindings) {
b.stageFlags |= shaderStages;
}
VkDescriptorSetLayoutCreateInfo info = {.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_SET_LAYOUT_CREATE_INFO};
info.pNext = pNext;
info.pBindings = bindings.data();
info.bindingCount = (uint32_t)bindings.size();
info.flags = flags;
VkDescriptorSetLayout set;
VK_CHECK(vkCreateDescriptorSetLayout(device, &info, nullptr, &set));
return set;
}
We are first looping through the bindings and adding the stage-flags. For each of the descriptor bindings within a descriptor set, they can be different between the fragment shader and vertex shader. We wont be supporting per-binding stage flags, and instead force it to be for the whole descriptor set.
Next we need to build the VkDescriptorSetLayoutCreateInfo, which we dont do much with, just hook it into the array of descriptor bindings. We then call vkCreateDescriptorSetLayout and return the set layout.
Descriptor Allocator
With the layout, we can now allocate the descriptor sets. Lets also write a allocator struct that will abstract it so that we can keep using it through the codebase.
struct DescriptorAllocator {
struct PoolSizeRatio{
VkDescriptorType type;
float ratio;
};
VkDescriptorPool pool;
void init_pool(VkDevice device, uint32_t maxSets, std::span<PoolSizeRatio> poolRatios);
void clear_descriptors(VkDevice device);
void destroy_pool(VkDevice device);
VkDescriptorSet allocate(VkDevice device, VkDescriptorSetLayout layout);
};
Descriptor allocation happens through VkDescriptorPool. Those are objects that need to be pre-initialized with some size and types of descriptors for it. Think of it like a memory allocator for some specific descriptors. Its possible to have 1 very big descriptor pool that handles the entire engine, but that means we need to know what descriptors we will be using for everything ahead of time. That can be very tricky to do at scale. Instead, we will keep it simpler, and we will have multiple descriptor pools for different parts of the project, and try to be more accurate with them.
One very important thing to do with pools is that when you reset a pool, it destroys all of the descriptor sets allocated from it. This is very useful for things like per-frame descriptors. That way we can have descriptors that are used just for one frame, allocated dynamically, and then before we start the frame we completely delete all of them in one go. This is confirmed to be a fast path by GPU vendors, and recommended to use when you need to handle per-frame descriptor sets.
The DescriptorAllocator we have just declared has functions to initialize a pool, clear the pool, and allocate a descriptor set from it.
Lets write the code now
void DescriptorAllocator::init_pool(VkDevice device, uint32_t maxSets, std::span<PoolSizeRatio> poolRatios)
{
std::vector<VkDescriptorPoolSize> poolSizes;
for (PoolSizeRatio ratio : poolRatios) {
poolSizes.push_back(VkDescriptorPoolSize{
.type = ratio.type,
.descriptorCount = uint32_t(ratio.ratio * maxSets)
});
}
VkDescriptorPoolCreateInfo pool_info = {.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_POOL_CREATE_INFO};
pool_info.flags = 0;
pool_info.maxSets = maxSets;
pool_info.poolSizeCount = (uint32_t)poolSizes.size();
pool_info.pPoolSizes = poolSizes.data();
vkCreateDescriptorPool(device, &pool_info, nullptr, &pool);
}
void DescriptorAllocator::clear_descriptors(VkDevice device)
{
vkResetDescriptorPool(device, pool, 0);
}
void DescriptorAllocator::destroy_pool(VkDevice device)
{
vkDestroyDescriptorPool(device,pool,nullptr);
}
We add creation and destruction functions. The clear function is not a delete, but a reset. It will destroy all of the descriptors created from the pool and put it back to initial state, but wont delete the VkDescriptorPool itself.
To initialize a pool, we use vkCreateDescriptorPool and give it an array of PoolSizeRatio. Thats a structure that contains a type of descriptor (same VkDescriptorType as on the bindings above ), alongside a ratio to multiply the maxSets parameter is. This lets us directly control how big the pool is going to be. maxSets controls how many VkDescriptorSets we can create from the pool in total, and the pool sizes give how many individual bindings of a given type are owned.
Now we need the last function, DescriptorAllocator::allocate. Here it is.
VkDescriptorSet DescriptorAllocator::allocate(VkDevice device, VkDescriptorSetLayout layout)
{
VkDescriptorSetAllocateInfo allocInfo = {.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_SET_ALLOCATE_INFO};
allocInfo.pNext = nullptr;
allocInfo.descriptorPool = pool;
allocInfo.descriptorSetCount = 1;
allocInfo.pSetLayouts = &layout;
VkDescriptorSet ds;
VK_CHECK(vkAllocateDescriptorSets(device, &allocInfo, &ds));
return ds;
}
We need to fill the VkDescriptorSetAllocateInfo. It needs the descriptor pool we will allocate from, how many descriptor sets to allocate, and the set layout.
Initializing the layout and descriptors
Lets add a new function to VulkanEngine and some new members we will use.
#include <vk_descriptors.h>
struct VulkanEngine{
public:
DescriptorAllocator globalDescriptorAllocator;
VkDescriptorSet _drawImageDescriptors;
VkDescriptorSetLayout _drawImageDescriptorLayout;
private:
void init_descriptors();
}
We will be storing one of those descriptor allocators in our engine as the global allocator. Then we need to store the descriptor set that will bind our render image, and the descriptor layout for that type of descriptor, which we will need later for creating the pipeline.
Remember to add the init_descriptors() function to the init() function of the engine, after sync_structures.
void VulkanEngine::init()
{
//other code
init_commands();
init_sync_structures();
init_descriptors();
//everything went fine
_isInitialized = true;
}
We can now begin writing the function
void VulkanEngine::init_descriptors()
{
//create a descriptor pool that will hold 10 sets with 1 image each
std::vector<DescriptorAllocator::PoolSizeRatio> sizes =
{
{ VK_DESCRIPTOR_TYPE_STORAGE_IMAGE, 1 }
};
globalDescriptorAllocator.init_pool(_device, 10, sizes);
//make the descriptor set layout for our compute draw
{
DescriptorLayoutBuilder builder;
builder.add_binding(0, VK_DESCRIPTOR_TYPE_STORAGE_IMAGE);
_drawImageDescriptorLayout = builder.build(_device, VK_SHADER_STAGE_COMPUTE_BIT);
}
}
We will first initialize the descriptor allocator with 10 sets, and we 1 descriptor per set of type VK_DESCRIPTOR_TYPE_STORAGE_IMAGE. Thats the type used for a image that can be written to from a compute shader.
Then, we use the layout builder to build the descriptor set layout we need, which is a layout with only 1 single binding at binding number 0, of type VK_DESCRIPTOR_TYPE_STORAGE_IMAGE too (matching the pool).
With this, we would be able to allocate up to 10 descriptors of this type for use with compute drawing.
We continue the function by allocating one of them, and writing it so that it points to our draw image.
void VulkanEngine::init_descriptors()
{
// other code
//allocate a descriptor set for our draw image
_drawImageDescriptors = globalDescriptorAllocator.allocate(_device,_drawImageDescriptorLayout);
VkDescriptorImageInfo imgInfo{};
imgInfo.imageLayout = VK_IMAGE_LAYOUT_GENERAL;
imgInfo.imageView = _drawImage.imageView;
VkWriteDescriptorSet drawImageWrite = {};
drawImageWrite.sType = VK_STRUCTURE_TYPE_WRITE_DESCRIPTOR_SET;
drawImageWrite.pNext = nullptr;
drawImageWrite.dstBinding = 0;
drawImageWrite.dstSet = _drawImageDescriptors;
drawImageWrite.descriptorCount = 1;
drawImageWrite.descriptorType = VK_DESCRIPTOR_TYPE_STORAGE_IMAGE;
drawImageWrite.pImageInfo = &imgInfo;
vkUpdateDescriptorSets(_device, 1, &drawImageWrite, 0, nullptr);
//make sure both the descriptor allocator and the new layout get cleaned up properly
_mainDeletionQueue.push_function([&]() {
globalDescriptorAllocator.destroy_pool(_device);
vkDestroyDescriptorSetLayout(_device, _drawImageDescriptorLayout, nullptr);
});
}
First we allocate a descriptor set object with the help of the allocator, of layout _drawImageDescriptorLayout which we created above. Then we need to update that descriptor set with our draw image. To do that, we need to use the vkUpdateDescriptorSets function. This function takes an array of VkWriteDescriptorSet which are the individual updates to perform. We create a single write, which points to binding 0 on the set we just allocated, and it has the correct type. It also points to a VkDescriptorImageInfo holding the actual image data we want to bind, which is going to be the imageview for our draw image.
With this done, we now have a descriptor set we can use to bind our draw image, and the layout we needed. We can finally proceed to creating the compute pipeline
The compute pipeline
With the descriptor set layout, we now have a way of creating the pipeline layout. There is one last thing we have to do before creating the pipeline, which is to load the shader code to the driver. In vulkan pipelines, to set shaders you need to build a VkShaderModule. We are going to add a function to load those as part of vk_pipelines.h/cpp
Add these includes to vk_pipelines.cpp
#include <vk_pipelines.h>
#include <fstream>
#include <vk_initializers.h>
Now add this function. Add it also to the header.
bool vkutil::load_shader_module(const char* filePath,
VkDevice device,
VkShaderModule* outShaderModule)
{
// open the file. With cursor at the end
std::ifstream file(filePath, std::ios::ate | std::ios::binary);
if (!file.is_open()) {
return false;
}
// find what the size of the file is by looking up the location of the cursor
// because the cursor is at the end, it gives the size directly in bytes
size_t fileSize = (size_t)file.tellg();
// spirv expects the buffer to be on uint32, so make sure to reserve a int
// vector big enough for the entire file
std::vector<uint32_t> buffer(fileSize / sizeof(uint32_t));
// put file cursor at beginning
file.seekg(0);
// load the entire file into the buffer
file.read((char*)buffer.data(), fileSize);
// now that the file is loaded into the buffer, we can close it
file.close();
// create a new shader module, using the buffer we loaded
VkShaderModuleCreateInfo createInfo = {};
createInfo.sType = VK_STRUCTURE_TYPE_SHADER_MODULE_CREATE_INFO;
createInfo.pNext = nullptr;
// codeSize has to be in bytes, so multply the ints in the buffer by size of
// int to know the real size of the buffer
createInfo.codeSize = buffer.size() * sizeof(uint32_t);
createInfo.pCode = buffer.data();
// check that the creation goes well.
VkShaderModule shaderModule;
if (vkCreateShaderModule(device, &createInfo, nullptr, &shaderModule) != VK_SUCCESS) {
return false;
}
*outShaderModule = shaderModule;
return true;
}
With this function, we first load the file into a std::vector<uint32_t>. This will store the compiled shader data, which we can then use on the call to vkCreateShaderModule. The create-info for a shader module needs nothing except the shader data as an int array. Shader modules are only needed when building a pipeline, and once the pipeline is built they can be safely destroyed, so we wont be storing them in the VulkanEngine class.
Back to VulkanEngine, lets add the new members we will need, and the init_pipelines() function alongside a init_background_pipelines() function. init_pipelines() will call the other pipeline initialization functions that we will add as the tutorial progresses.
class VulkanEngine{
public:
VkPipeline _gradientPipeline;
VkPipelineLayout _gradientPipelineLayout;
private:
void init_pipelines();
void init_background_pipelines();
}
Add it to the init function, and add the vk_pipelines.h include to the top of the file. The init_pipelines() function will call init_background_pipelines()
#include <vk_pipelines.h>
void VulkanEngine::init()
{
//other code
init_commands();
init_sync_structures();
init_descriptors();
init_pipelines();
//everything went fine
_isInitialized = true;
}
void VulkanEngine::init_pipelines()
{
init_background_pipelines();
}
Lets now begin creating the pipeline. The first thing we will do is create the pipeline layout.
void VulkanEngine::init_background_pipelines()
{
VkPipelineLayoutCreateInfo computeLayout{};
computeLayout.sType = VK_STRUCTURE_TYPE_PIPELINE_LAYOUT_CREATE_INFO;
computeLayout.pNext = nullptr;
computeLayout.pSetLayouts = &_drawImageDescriptorLayout;
computeLayout.setLayoutCount = 1;
VK_CHECK(vkCreatePipelineLayout(_device, &computeLayout, nullptr, &_gradientPipelineLayout));
}
To create a pipeline, we need an array of descriptor set layouts to use, and other configuration such as push-constants. On this shader we wont need those so we can skip them, leaving only the DescriptorSetLayout.
Now, we are going to create the pipeline object itself by loading the shader module and adding it plus other options into a VkComputePipelineCreateInfo.
void VulkanEngine::init_background_pipelines()
{
//layout code
VkShaderModule computeDrawShader;
if (!vkutil::load_shader_module("../../shaders/gradient.comp.spv", _device, &computeDrawShader))
{
fmt::print("Error when building the compute shader \n");
}
VkPipelineShaderStageCreateInfo stageinfo{};
stageinfo.sType = VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO;
stageinfo.pNext = nullptr;
stageinfo.stage = VK_SHADER_STAGE_COMPUTE_BIT;
stageinfo.module = computeDrawShader;
stageinfo.pName = "main";
VkComputePipelineCreateInfo computePipelineCreateInfo{};
computePipelineCreateInfo.sType = VK_STRUCTURE_TYPE_COMPUTE_PIPELINE_CREATE_INFO;
computePipelineCreateInfo.pNext = nullptr;
computePipelineCreateInfo.layout = _gradientPipelineLayout;
computePipelineCreateInfo.stage = stageinfo;
VK_CHECK(vkCreateComputePipelines(_device,VK_NULL_HANDLE,1,&computePipelineCreateInfo, nullptr, &_gradientPipeline));
}
First we load the computeDrawShader VkShaderModule by using the function we created just now. We will check for error as its very common for it to fail if the file is wrong. Keep in mind that the paths here are configured to work for the default windows + msvc build folders. If you are using any other option, check that the file paths are correct. Consider abstracting the path yourself to work from a folder set in a config file.
Then, we need to connect the shader into a VkPipelineShaderStageCreateInfo. The thing to note here is that we are giving it the name of the function we want the shader to use, which is going to be main(). It is possible to store multiple compute shader variants on the same shader file, by using different entry point functions and then setting them up here.
Last, we fill the VkComputePipelineCreateInfo. We will need the stage info for the compute shader, and the layout. We can then call vkCreateComputePipelines.
At the end of the function, we will do proper cleanup of the structures so that they get deleted at the end of the program through the deletion queue.
vkDestroyShaderModule(_device, computeDrawShader, nullptr);
_mainDeletionQueue.push_function([&]() {
vkDestroyPipelineLayout(_device, _gradientPipelineLayout, nullptr);
vkDestroyPipeline(_device, _gradientPipeline, nullptr);
});
We can destroy the shader module directly on the function, we created the pipeline so we have no need for it anymore. With the pipeline and its layout, we need to wait until the end of the program.
We are now ready to draw with it.
Drawing with compute
Go back to the draw_background() function, we will replace the vkCmdClear with a compute shader invocation.
// bind the gradient drawing compute pipeline
vkCmdBindPipeline(cmd, VK_PIPELINE_BIND_POINT_COMPUTE, _gradientPipeline);
// bind the descriptor set containing the draw image for the compute pipeline
vkCmdBindDescriptorSets(cmd, VK_PIPELINE_BIND_POINT_COMPUTE, _gradientPipelineLayout, 0, 1, &_drawImageDescriptors, 0, nullptr);
// execute the compute pipeline dispatch. We are using 16x16 workgroup size so we need to divide by it
vkCmdDispatch(cmd, std::ceil(_drawExtent.width / 16.0), std::ceil(_drawExtent.height / 16.0), 1);
First we need to bind the pipeline using vkCmdBindPipeline. As the pipeline is a compute shader, we use VK_PIPELINE_BIND_POINT_COMPUTE. Then, we need to bind the descriptor set that holds the draw image so that the shader can access it. Finally, we use vkCmdDispatch to launch the compute shader. We will decide how many invocations of the shader to launch (remember, the shader is 16x16 per workgroup) by dividing the resolution of our draw image by 16, and rounding up.
If you run the program at this point, it should display this image. If you have an error when loading the shader, make sure you have the shaders built by re-running CMake, and rebuilding the Shaders target. This target will not build automatically when building engine, so you must rebuild it every time shaders change.
Next: Setting up IMGUI